

Μια πιο προσεκτική ματιά σε ένα πρόβλημα κατηγοριοποίησης εγγράφων

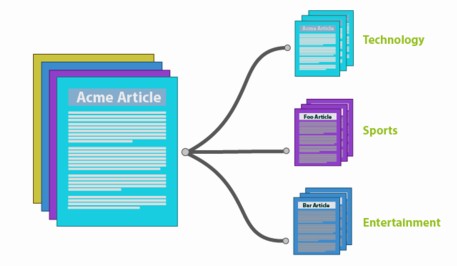 Αξίζει να εξεταστούν τα βήματα που είναι απαραίτητα για να γίνει η κατηγοριοποίηση των εγγράφων/σχολίων σε θετικά ή αρνητικά ή ακόμα και σε περισσότερες κατηγορίες, όπως για παράδειγμα η κατηγορία ουδέτερων σχολίων.
Αξίζει να εξεταστούν τα βήματα που είναι απαραίτητα για να γίνει η κατηγοριοποίηση των εγγράφων/σχολίων σε θετικά ή αρνητικά ή ακόμα και σε περισσότερες κατηγορίες, όπως για παράδειγμα η κατηγορία ουδέτερων σχολίων.
1. Τα δεδομένα
Η στατιστική μέθοδος κατηγοριοποίησης εγγράφων απαιτεί μία συλλογή από έγγραφα/σχόλια/κείμενα που έχουν τοποθετηθεί από κάποιον άνθρωπο στην κατάλληλη κατηγορία τους. Η ποιότητα του σετ δεδομένων είναι με διαφορά ο σημαντικότερος παράγοντας. Το σετ δεδομένων πρέπει να είναι αρκετά μεγάλο και να έχει κατηγορίες με κοντινό αριθμό εγγράφων. Προβλήματα, όπως σχόλια που περιέχουν και αρνητικό και θετικό χαρακτήρα, είναι συχνά σε πραγματικά σχόλια και αντιμετωπίζονται με διάφορους τρόπους, όπως με μεγάλο αριθμό εγγράφων για να μπορεί ο αλγόριθμος να «ξεχωρίσει» τις κατηγορίες.
2. Επεξεργασία δεδομένων
Η επεξεργασία των εγγράφων είναι επίσης σημαντικό βήμα. Η κάθε λέξη (ή σύμβολο όπως emoticon) αποτελεί ξεχωριστή μεταβλητή/παράγοντα. Έτσι κατασκευάζεται ένα πίνακας (Term Document Matrix) όπου η κάθε γραμμή αντιπροσωπεύει ένα διαφορετικό σχόλιο/έγγραφο και κάθε στήλη διαφορετική λέξη/όρο. Έτσι η κάθε γραμμή, έχει σαν στοιχεία τη συχνότητα που εμφανίζεται ο κάθε όρος στο σχόλιο που αφορά τη γραμμή. Μια άλλη κοινή μεθοδολογία είναι αντί για τις συχνότητες χρησιμοποιούνται TF-IDF (term frequency-inverse document frequency) βάρη. Για κάθε φορά που η λέξη εμφανίζεται σε ένα σχόλια αυξάνεται το βάρος της ενώ μειώνεται ανάλογα με το πόσο συχνά εμφανίζεται σε όλο το σετ των εγγράφων\σχολίων. Έτσι, μειώνεται το βάρος που δίνεται σε λέξεις που εμφανίζονται πολύ συχνά στο σετ δεδομένων αλλά δεν είναι χρήσιμες στην κατηγοριοποίηση, όπως άρθρα κλπ. Η επεξεργασία περιλαμβάνει και άλλα βήματα που είναι στην κρίση κάθε αναλυτή, όπως η αφαίρεση κοινών λέξεων όπως άρθρα, ή πολύ σπάνιων λέξεων που εμφανίζονται λίγες φορές σε ολόκληρο το σετ εγγράφων. Τέλος, πέρα από τον ορισμό των λέξεων σαν μεταβλητές μπορεί ο αναλυτής να ορίσει και ζευγάρια λέξεων ή τριάδες λέξεων κλπ ή ακόμα και συγκεκριμένες φράσεις που έχουν προκύψει από τη περιγραφική ανάλυση.
3. Αλγόριθμος classifier και στρατηγική
Υπάρχουν πολλοί αλγόριθμοι που μπορούν να χρησιμοποιηθούν για τη κατηγοριοποίηση εγγράφων. Μπορεί κανείς χωρίς να έχει γνώση αλγορίθμων Μηχανικής Μάθησης να φτιάξει έναν τέτοιο αλγόριθμο. Το πιο απλό θα ήταν με βάση τις λέξεις που εμφανίζονται σε κάθε σχόλιο και την συχνότητα τους. Γενικά, επιλέγεται αλγόριθμος με βάση τον σκοπό που έχει ο αναλυτής. Στην περίπτωση της Sentiment analysis χρησιμοποιούνται διάφοροι γνωστοί αλγόριθμοι όπως Support Vector Machines, Naïve Bayes, Decision Trees και πολλοί άλλοι.
Αυτά είναι σε γενικές γραμμές τα βήματα που έχει κάποιος να κάνει για να αναλύσει κείμενα/έγγραφα/σχόλια. Στις μεθόδους με επίβλεψη (supervised learning) το μοντέλο δημιουργείται βασιζόμενο στο training set. Έτσι, η ποιότητα του training set είναι ο κύριος παράγοντας για τη ποιότητα του μοντέλου. Από την άλλη, η απαίτηση για ένα training set με προκαθορισμένες τις κατηγορίες είναι από μόνο του ένα μειονέκτημα.

Newsletter




